Perplexity citation rate benchmark: what good looks like
How to benchmark Perplexity citation rate by prompt intent, separate mention rate from source ownership, and improve the prompts where competitors are cited instead of you.
Perplexity citation rate is easy to misread. A team sees one answer citing its site, celebrates the win, and then misses the harder truth: competitors may still own most of the cited source slots on the prompts that influence buying decisions.
The fast decision rule: benchmark Perplexity citation rate by prompt intent, not as one blended score. A 10% citation rate on comparison prompts can matter more than a 60% rate on definition prompts, because comparison answers are where buyers build shortlists.
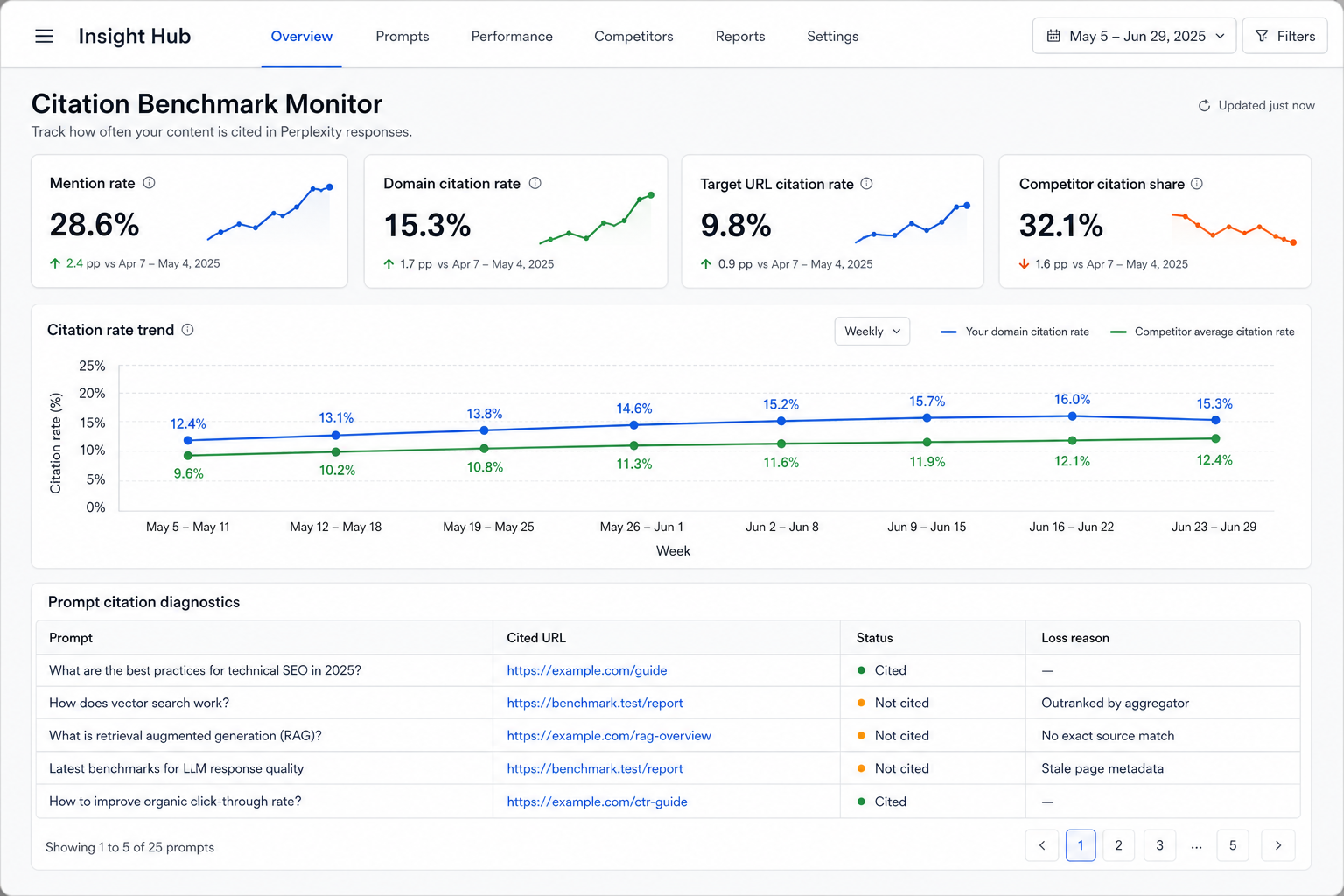
Use this guide after you have the basics from Perplexity citation monitoring. If you still need the raw capture fields for cited URLs, citation position, target URL match, and loss reason, start with Perplexity citation tracking. If you still need the page-shape fixes, pair it with the Perplexity SEO checklist and the source-selection guide on how Perplexity chooses sources. If ChatGPT is the surface you report first, use the companion ChatGPT citation rate benchmark.
What is a good Perplexity citation rate?
A good Perplexity citation rate is one that improves on the prompts where buyers need proof, comparison, or a source-backed recommendation. For early B2B SaaS programs, the useful benchmark is not a universal percentage. It is whether your domain is cited more often on high-intent prompts than last month, and whether competitor source share is falling.
Perplexity citation rate is the percentage of tracked Perplexity answers that cite your domain for a fixed prompt set. It should be reported separately from brand mention rate, because Perplexity says its answers include citations and links to original sources, and a brand can be named without owning one of those source links.
Do not compare your number against a random public benchmark without checking the prompt mix. A prompt set full of definitions will produce a different citation rate from one full of "best tool," "alternative," "vs," pricing, and failure-mode prompts.
How do you calculate Perplexity citation rate?
Calculate Perplexity citation rate by dividing the number of tracked answers that cite your domain by the total number of relevant prompt runs. Then calculate a second metric: target URL citation rate, which only counts answers citing the page that should have owned the prompt.
Use this formula:
| Metric | Formula | What it tells you |
|---|---|---|
| Brand mention rate | Answers naming your brand / total prompt runs | Whether Perplexity includes you in the answer |
| Domain citation rate | Answers citing your domain / total prompt runs | Whether your site owns source slots |
| Target URL citation rate | Answers citing the intended URL / total prompt runs | Whether the right page is being used |
| Owned citation share | Your cited URLs / all cited URLs in tracked answers | Whether competitors still control the source map |
| First-cited rate | Answers where your domain is the first cited source / citation-producing runs | Whether your source anchors the answer |
If you run each prompt three times, count runs rather than unique prompts. Perplexity answers can drift. Multiple samples make the benchmark less fragile, especially when the prompt asks for tools, vendors, examples, or current sources.
What benchmark should you use by prompt intent?
Use intent-weighted benchmarks. Definition prompts should have the highest achievable citation rate, but they usually matter less commercially. Comparison, alternatives, and pricing-adjacent prompts often start lower and deserve more attention because they shape buyer shortlists.
Start with this practical scorecard:
| Prompt intent | Example query | Early benchmark | Strong benchmark | Fix priority |
|---|---|---|---|---|
| Definition | "what is generative engine optimization" | 20-40% | 50-70% | Medium |
| Workflow | "how do I track cited URLs in Perplexity" | 10-25% | 35-55% | High |
| Failure mode | "why does Perplexity cite competitors instead of my website" | 5-20% | 30-50% | High |
| Comparison | "Tracemetry vs Profound for AI visibility tracking" | 5-15% | 25-45% | Very high |
| Alternatives | "best Profound alternatives for AI visibility" | 5-15% | 25-45% | Very high |
| Pricing-adjacent | "which AI visibility tool is worth paying for" | 0-10% | 20-35% | Very high |
Treat these as operating bands, not scientific laws. A new category, weak domain, or tiny content library may start below them. A mature publication with strong third-party mentions may exceed them. The point is to set a baseline that forces the team to fix the prompts that actually move pipeline.
Why is my Perplexity citation rate lower than my mention rate?
Your citation rate is lower than your mention rate when Perplexity knows the brand but does not trust your site as the cleanest source for the answer. That gap is common. It usually means your entity is visible, but another page has clearer evidence, fresher examples, better page structure, stronger authority, or a more exact match to the prompt.
Classify the gap before shipping new content:
| Pattern | What it means | First fix |
|---|---|---|
| Brand named, competitor cited | You are considered, but competitor owns source proof | Improve the source page for that prompt |
| Brand named, publisher cited | Third-party proof is shaping the answer | Add source-worthy evidence and earn external mentions |
| Domain cited, wrong URL | Internal source map is unclear | Link the pillar, checklist, and specific page with clearer anchors |
| Domain cited late | Your source supports a secondary claim | Add a stronger direct answer and table near the top |
| No citation, no mention | Retrieval or category clarity is weak | Create or rewrite the page that should match the prompt |
Google's structured data guidance says markup should describe visible page content, and Perplexity's visible citation model makes the same principle practical: the page itself has to carry the answer. Schema can clarify the source; it cannot substitute for it.
Which prompt set gives a reliable benchmark?
A reliable Perplexity citation-rate benchmark uses a fixed prompt set across category, surface-specific, workflow, comparison, alternatives, failure-mode, and pricing-adjacent questions. The prompts should sound like buyer questions, not just keywords pasted into a spreadsheet.
Use 40-80 prompts for the first benchmark:
| Bucket | Count | Example prompt |
|---|---|---|
| Category discovery | 8-12 | "what are the best AI visibility tools for B2B SaaS" |
| Surface-specific | 6-10 | "how do I track Perplexity citations for my brand" |
| Workflow | 6-10 | "how do I improve Perplexity citation rate every week" |
| Comparison | 8-12 | "Tracemetry vs Profound for AI search monitoring" |
| Alternatives | 6-10 | "best Profound alternatives for startups" |
| Failure mode | 8-12 | "why does Perplexity cite my competitors instead of my website" |
| Pricing-adjacent | 4-8 | "which AI visibility monitoring tool is worth paying for" |
Add entity terms naturally when they help disambiguate the surface and use case: Perplexity, cited URLs, citation rate, source ownership, AI visibility tracking, AI brand monitoring, generative engine optimization, answer engine optimization, B2B SaaS, comparison pages, alternatives pages, FAQ schema, Article schema, and buyer shortlists.
How often should you re-measure the benchmark?
Re-measure Perplexity citation rate weekly for active programs and monthly for passive monitoring. Weekly is fast enough to catch movement after page updates, but slow enough to avoid reacting to every answer variation.
Use the same prompt wording, locale, and sampling approach each time. If you add new prompts, label them as a new cohort instead of mixing them into the old baseline. Otherwise a "citation-rate improvement" may only mean the team added easier prompts.
For each run, save:
- Prompt text and prompt bucket
- Date, country, and surface
- Brands named
- Cited domains and cited URLs
- Citation position
- Target URL expected
- Loss reason
- Page fix shipped
- Re-measurement date
This turns the benchmark into an action queue. Without the loss reason and next page fix, the report is just a scoreboard.
How do you improve a weak Perplexity citation benchmark?
Improve the benchmark by fixing the highest-intent prompt where your domain is absent or the wrong URL is cited. Do not start with every prompt at once. Pick one source gap, make the target page easier to retrieve, parse, trust, and cite, then re-measure the same prompt after the page is live.
Use this fix order:
- Pick the highest-weight loss. Comparison, alternatives, and pricing-adjacent prompts beat definitions.
- Inspect the cited competitor URL. Look at title, first answer block, tables, sources, FAQ, schema, and freshness.
- Improve the intended page. Add a 40-80 word direct answer, a decision table, explicit entity language, and source-backed claims.
- Clarify internal links. Link from AI visibility tracking, content that AI cites, schema markup for AI search, and relevant Perplexity posts.
- Align FAQ and schema. The FAQ answers in schema should match visible text on the page.
- Re-measure after 7-14 days. Track target URL citation rate, not only domain citation rate.
If the answer cites a third-party publication instead of any vendor, the fix may include earned proof: analyst pages, partner pages, reviews, community discussions, or category comparisons. Your own page can be excellent and still lose when Perplexity needs outside validation.
What should a weekly citation-rate report show?
A weekly Perplexity citation-rate report should show the score, the prompts behind the score, the competitor URLs winning source slots, the page fixes shipped, and whether prior fixes changed the next run. The report should end with one concrete content or source action.
Use this compact report format:
| Section | What to include |
|---|---|
| Executive score | Mention rate, domain citation rate, target URL citation rate, owned citation share |
| High-intent movement | Comparison, alternatives, failure-mode, and pricing-adjacent changes |
| Competitor source wins | Domains and URLs cited instead of yours |
| Recovered prompts | Prompts that moved from absent to mentioned or cited |
| Page fixes shipped | URLs updated, internal links added, schema changed, sources added |
| Next action | One page or proof gap to fix this week |
For a first baseline, run the free Tracemetry audit. For weekly tracking, Tracemetry Pro keeps the prompt set stable, records citations separately from mentions, turns losses into source-grounded briefs, and shows whether citation ownership improves after each fix.
Start with the benchmark, then fix one source gap
Do not ask "what is our Perplexity visibility?" as one giant question. Ask: which prompts mention us, which prompts cite us, which URL was cited, which competitor owns the source slot, and which one fix would change next week's score?
That is the difference between a vanity AI visibility chart and a useful Perplexity citation-rate benchmark. The chart says whether you are present. The benchmark tells you what to fix next.
For the surrounding workflow, read Perplexity citation monitoring, how Perplexity chooses sources, and how to optimize content for Perplexity. Then run the free audit to find the first source gap worth fixing.
Frequently asked questions
What is Perplexity citation rate?
Perplexity citation rate is the percentage of tracked Perplexity answers that cite your domain for a fixed prompt set. It should be measured separately from brand mention rate because Perplexity can name your brand without citing your website.
What is a good Perplexity citation rate?
A good Perplexity citation rate depends on prompt intent. Definition prompts may reach higher rates, while comparison, alternatives, and pricing-adjacent prompts often start lower but matter more commercially. The useful benchmark is week-over-week improvement on high-intent prompts.
How do I calculate Perplexity citation rate?
Divide the number of tracked Perplexity answers that cite your domain by the total number of relevant prompt runs. Also calculate target URL citation rate so you know whether Perplexity cited the page that should have owned the answer.
Why is citation rate lower than mention rate?
Citation rate is lower than mention rate when Perplexity knows your brand but uses another source to support the answer. Common causes are weak page shape, stale examples, unclear entity language, stronger competitor evidence, or a third-party source that looks more trustworthy.
How often should I benchmark Perplexity citations?
Benchmark weekly for active AI visibility programs and monthly for passive monitoring. Keep the prompt wording, locale, and sampling approach consistent so the score reflects source-ownership movement instead of prompt-list changes.
See your own AI visibility today.
Free public report. 60 seconds. No signup. Or get started on Pro to track 250 prompts continuously.