ChatGPT Share of Voice: formula, prompt set, and report
How to calculate ChatGPT share of voice, build the right prompt set, separate mention rate from citation rate, and turn competitor SOV losses into page fixes.
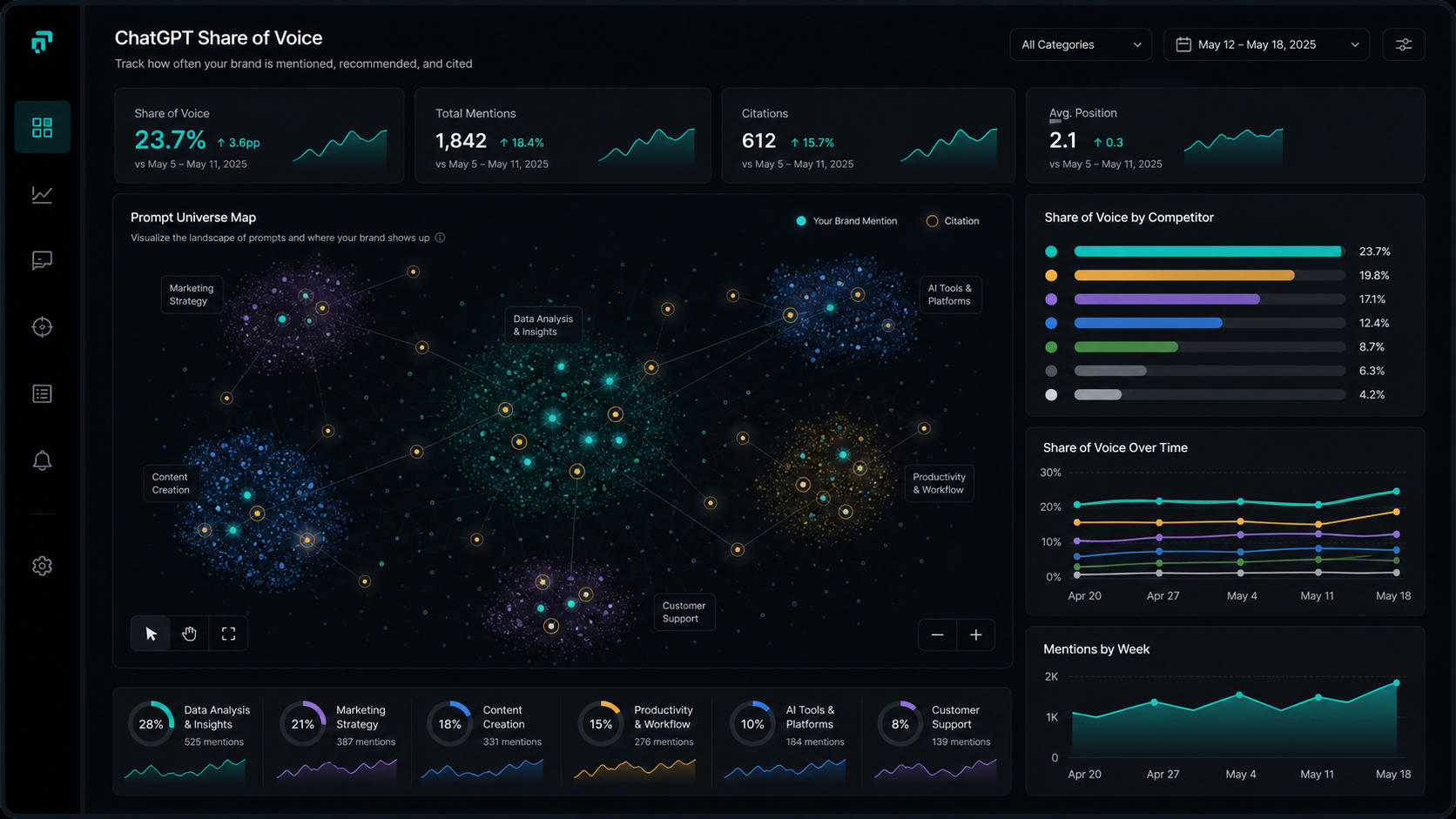
ChatGPT share of voice tells you whether ChatGPT names your brand more often than competitors for the buyer prompts that matter. The painful part is that most teams still look at Google rankings while ChatGPT is quietly shaping shortlists, comparisons, and "best tool for..." answers before the buyer ever clicks.
Use the fast rule: measure ChatGPT SOV from a locked prompt set, an approved competitor set, and a weekly window. If you change the prompts every week, count every stray mention, or blend ChatGPT with other AI surfaces, the number becomes theater.
This is the ChatGPT-specific version of the broader AI share of voice formula. Use it when leadership asks, "Are we the brand ChatGPT recommends, or are competitors taking that surface?"
What is ChatGPT share of voice?
ChatGPT share of voice is the percentage of approved brand mentions inside ChatGPT answers that belong to your brand, measured across a fixed prompt set and time window. It turns "do we show up in ChatGPT?" into a comparable weekly number instead of a few screenshots.
ChatGPT share of voice is the ChatGPT-only slice of AI share of voice. If 100 approved brand mentions appear across your tracked ChatGPT prompts this week, and 18 of those mentions are your brand, your ChatGPT SOV is 18%. Compute it separately from Claude, Perplexity, Gemini, and Google AI Overviews because the same prompt can produce different winners on each surface.
OpenAI's ChatGPT Search documentation explains that search answers can include source links and a sources panel. That matters because a useful SOV report should separate two signals: whether ChatGPT names your brand and whether it cites your domain.
How do you calculate ChatGPT share of voice?
Calculate ChatGPT SOV by counting your brand mentions, counting competitor mentions from the approved competitor set, and dividing your mentions by total approved mentions. Run the same prompts on the same cadence so the movement is real.
Use this formula:
ChatGPT SOV = your ChatGPT mentions / total approved brand mentions in ChatGPT answers
Example:
| Brand | Mentions across weekly ChatGPT prompt set | Share of voice |
|---|---|---|
| Your brand | 18 | 18% |
| Competitor A | 31 | 31% |
| Competitor B | 22 | 22% |
| Competitor C | 17 | 17% |
| Competitor D | 12 | 12% |
| Total approved mentions | 100 | 100% |
That simple score is useful, but the weighted score is better. A bottom-funnel prompt like "best AI visibility tool for a B2B SaaS team" should count more than "what is AI visibility." Use 1x for awareness prompts, 2x for consideration prompts, and 4x for decision prompts.
Which prompts belong in a ChatGPT SOV set?
A ChatGPT SOV prompt set should mirror buyer jobs: discovery, shortlisting, comparison, alternatives, failure modes, pricing-adjacent questions, and implementation workflows. Do not copy an SEO keyword list into ChatGPT. Keywords help with language; prompts measure assistant behavior.
Start with 40-80 prompts:
| Prompt bucket | Count | Example ChatGPT query |
|---|---|---|
| Category discovery | 8-12 | "what is the best way to track AI search visibility" |
| Tool shortlisting | 10-15 | "best ChatGPT SEO tools for a startup marketing team" |
| Comparison | 8-12 | "Tracemetry vs Profound for AI visibility tracking" |
| Alternatives | 6-10 | "best Otterly alternative for weekly AI search reporting" |
| Failure mode | 6-10 | "why does ChatGPT mention competitors instead of my brand" |
| Workflow | 6-10 | "how do I report ChatGPT brand mentions to leadership" |
Add entity terms that disambiguate the surface and use case: ChatGPT Search, OpenAI, brand mentions, source links, citations, citation rate, prompt tracking, competitor share of voice, AI visibility report, B2B SaaS, comparison pages, alternatives pages, pricing pages, and FAQPage schema.
For a ready-made starting library, adapt the ChatGPT SEO prompts set, use ChatGPT recommendation tracking when you need to classify shortlist outcomes, then use ChatGPT citation tracking when you need the cited-URL layer.
What should you count as a brand mention?
Count a brand mention only when ChatGPT presents the brand as a relevant option, source, example, or recommendation for the prompt. Do not count navigation boilerplate, hallucinated brand names, unrelated context, or cases where the user already named the brand in the prompt.
Use this mention-quality table:
| Answer behavior | Count it? | Why |
|---|---|---|
| ChatGPT lists your brand as one of the recommended tools | Yes | It shapes the buyer shortlist |
| ChatGPT cites your domain but does not name the brand | Separate metric | This is citation rate, not mention SOV |
| ChatGPT mentions your brand only because the prompt named it | No | Prompted mentions inflate the score |
| ChatGPT names a partner or integration page that references you | Usually no | The buyer is not seeing you as the option |
| ChatGPT names a competitor and cites their comparison page | Yes | This is a competitor SOV win and likely a source-ownership loss |
This is where manual review matters. A fuzzy parser can find names, but it cannot always tell whether the answer actually recommended the brand. For small prompt sets, review borderline mentions. For larger sets, route uncertain mentions to an approval queue before they hit the SOV denominator.
How often should you measure ChatGPT SOV?
Measure ChatGPT share of voice weekly for normal operations and daily only during launches, rebrands, pricing changes, outages, or major content pushes. Weekly is frequent enough to catch movement without letting random answer variance dominate the report.
Use three rules:
- Keep prompt wording stable. Rewrite prompts only in scheduled refreshes, not after a bad week.
- Run enough samples. One answer can be noisy; three samples per important prompt is a better operating baseline.
- Report the delta. The change from last week matters more than the absolute score in isolation.
If ChatGPT SOV rises but citation rate stays flat, you are getting brand awareness without source ownership. If citation rate rises but SOV stays flat, your pages are being used as evidence while competitors still own the recommendation.
How do you diagnose a low ChatGPT share of voice score?
A low ChatGPT SOV score usually comes from one of five problems: missing pages, weak page structure, stale content, weak entity clarity, or competitors owning better third-party proof. Diagnose the loss before writing new content.
Use this fix map:
| Loss pattern | Likely cause | Best next move |
|---|---|---|
| Competitor named, you absent | Missing buyer-intent page | Publish the exact comparison, alternatives, or use-case page the prompt needs |
| You named, competitor first | Weak positioning or proof | Add decision criteria, numbers, examples, and third-party validation |
| You cited, competitor recommended | Source page informs the answer but does not sell the choice | Add a clear "choose X if..." section and stronger CTA |
| You appear on Perplexity but not ChatGPT | ChatGPT's retrieval or memory layer has weaker signals | Improve Bing-indexable content, freshness, internal links, and external mentions |
| Score swings every week | Prompt set or sample size is too small | Expand to 40-80 prompts and keep the set locked |
Google's guidance for AI features and structured data both point toward the same practical rule: make important information visible, useful, and machine-readable. For ChatGPT SOV, that means direct answers, clear page titles, current dates, comparison tables, FAQ content, and internal links from related pages.
What is the difference between SOV, mention rate, and citation rate?
Share of voice compares your brand against competitors. Mention rate compares your brand against the total number of prompt runs. Citation rate measures whether your domain was used as a source. You need all three because each one answers a different business question.
| Metric | Formula | Business question |
|---|---|---|
| Mention rate | Prompt runs naming you / total prompt runs | Does ChatGPT include us at all? |
| ChatGPT SOV | Your mentions / approved brand mentions | Are we winning the shortlist against competitors? |
| Citation rate | Prompt runs citing your domain / total prompt runs | Does ChatGPT use our site as evidence? |
| First-named rate | Runs where you are the first recommended brand / runs naming you | Are we the default choice or a trailing option? |
| Weighted SOV | Intent-weighted mentions / intent-weighted approved mentions | Are we winning the prompts closest to revenue? |
The highest-priority gaps are decision-stage prompts where a competitor has both SOV and citations. That means ChatGPT is naming them and giving the buyer a source path to trust them.
Add ChatGPT first-named rate when the answer includes a shortlist or ranked recommendation. SOV tells you whether you were named; first-named rate tells you whether you were the default recommendation at the top of the answer.
How do you improve ChatGPT share of voice?
Improve ChatGPT SOV by fixing the prompts where competitors are already winning. The shortest path is not publishing generic "what is" content. It is creating or upgrading the page ChatGPT should use for that exact buyer question.
The operating sequence:
- Run a GEO audit or a ChatGPT-only prompt set.
- Sort losses by weighted intent, not raw prompt count.
- Identify the page that should win each prompt.
- Rewrite the opener so it answers the prompt in 40-80 words.
- Add a decision table, examples, visible FAQ content, and current product details.
- Link the page from related ChatGPT SEO, AI visibility report, and comparison pages.
- Re-measure the same prompts the next week.
For teams that want the loop automated, Tracemetry Pro tracks prompts, surfaces competitor SOV gaps, generates source-grounded briefs, helps draft the fix, and re-measures the prompt set after publishing.
What should a ChatGPT SOV report include?
A good ChatGPT SOV report is short, comparable, and tied to action. It should show the score, the prompts behind the score, the competitors that moved, the cited URLs, and the next page fixes.
Minimum report structure:
- Weekly ChatGPT SOV, mention rate, citation rate, and first-named rate
- Top gained prompts and top lost prompts
- Competitor movement by prompt bucket
- Cited URLs where competitors earned the source slot
- Pages updated or published since the last run
- Next fixes with owner and re-measure date
The report should end with one decision: update an existing page, publish a missing page, improve schema and internal links, or earn third-party proof. If the report ends with "keep monitoring," it is not operational enough.
FAQ
What is ChatGPT share of voice? ChatGPT share of voice is your percentage of approved brand mentions inside ChatGPT answers across a fixed prompt set and time window. It measures whether ChatGPT recommends your brand more or less often than competitors for buyer-relevant prompts.
How is ChatGPT share of voice different from AI share of voice? ChatGPT share of voice only measures ChatGPT. AI share of voice measures multiple AI surfaces such as ChatGPT, Claude, Perplexity, Gemini, and Google AI Overviews. Keep them separate because the same prompt can produce different winners on each system.
How many prompts do I need for ChatGPT SOV tracking? Start with 40-80 prompts across category, shortlisting, comparison, alternatives, workflow, failure-mode, and pricing-adjacent intent. Fewer than 20 prompts is easy to cherry-pick. Larger programs can expand once the team is acting on the findings.
Should I count citations in ChatGPT share of voice? No. Count citations as a separate citation-rate metric. A brand mention shows shortlist presence; a citation shows source ownership. The strongest wins have both, but merging them hides what needs to be fixed.
Can I measure ChatGPT share of voice manually? Yes. Put 40 prompts in a spreadsheet, run them in ChatGPT on the same day each week, record approved brand mentions, and compute your mentions divided by total approved brand mentions. Manual tracking works early; it gets painful once you add samples, competitors, and cited URLs.
What is a good ChatGPT share of voice score? A category leader may hold 40-70% SOV on a focused prompt set. A credible challenger often sits in the 10-30% range. The exact benchmark matters less than weekly movement on high-intent prompts and whether your citation rate is improving with it.
Start with the prompts ChatGPT already answers
Run the free Tracemetry audit to see whether ChatGPT, Claude, and Perplexity mention your brand, cite your site, and recommend competitors. If the snapshot shows a gap, use Tracemetry Pro to track the full prompt set, find ChatGPT SOV losses, publish source-grounded fixes, and re-measure the prompts that matter.
Sources: OpenAI ChatGPT Search, Google AI features and your website, Google structured data introduction, Bing Webmaster Guidelines.
Frequently asked questions
What is ChatGPT share of voice?
ChatGPT share of voice is your percentage of approved brand mentions inside ChatGPT answers across a fixed prompt set and time window. It measures whether ChatGPT recommends your brand more or less often than competitors for buyer-relevant prompts.
How is ChatGPT share of voice different from AI share of voice?
ChatGPT share of voice only measures ChatGPT. AI share of voice measures multiple AI surfaces such as ChatGPT, Claude, Perplexity, Gemini, and Google AI Overviews. Keep them separate because the same prompt can produce different winners on each system.
How many prompts do I need for ChatGPT SOV tracking?
Start with 40-80 prompts across category, shortlisting, comparison, alternatives, workflow, failure-mode, and pricing-adjacent intent. Fewer than 20 prompts is easy to cherry-pick. Larger programs can expand once the team is acting on the findings.
Should I count citations in ChatGPT share of voice?
No. Count citations as a separate citation-rate metric. A brand mention shows shortlist presence; a citation shows source ownership. The strongest wins have both, but merging them hides what needs to be fixed.
Can I measure ChatGPT share of voice manually?
Yes. Put 40 prompts in a spreadsheet, run them in ChatGPT on the same day each week, record approved brand mentions, and compute your mentions divided by total approved brand mentions. Manual tracking works early; it gets painful once you add samples, competitors, and cited URLs.
What is a good ChatGPT share of voice score?
A category leader may hold 40-70% SOV on a focused prompt set. A credible challenger often sits in the 10-30% range. The exact benchmark matters less than weekly movement on high-intent prompts and whether your citation rate is improving with it.
See your own AI visibility today.
Free public report. 60 seconds. No signup. Or get started on Pro to track 250 prompts continuously.