AI answer accuracy monitoring: fix wrong AI product answers
How to monitor AI answer accuracy across ChatGPT, Perplexity, Gemini, Claude, and Google AI Overviews: prompts, stale claims, wrong citations, scoring, and fixes.
AI answer accuracy monitoring is the process of checking whether ChatGPT, Perplexity, Gemini, Claude, and Google AI answers describe your brand, product, pricing, features, integrations, and competitors correctly. The painful problem is that AI visibility can look good while the answer is quietly wrong.
The fast rule: track answer accuracy separately from brand mentions and citations. A mention gets you into the answer. A citation gives the buyer a source path. Accuracy decides whether the answer helps the buyer trust you or sends sales into cleanup mode.
This guide sits inside the same operating loop as AI brand monitoring, AI visibility tracking, AI search competitor mentions, and the weekly AI visibility report. Use it when the question is not just "are we showing up?" but "is the answer saying the right thing?"
If the answer is factually correct but still discourages the buyer, use AI search sentiment monitoring next. It labels positive, neutral, mixed, negative, wrong, and unverifiable framing so sentiment problems do not get buried inside accuracy scores.
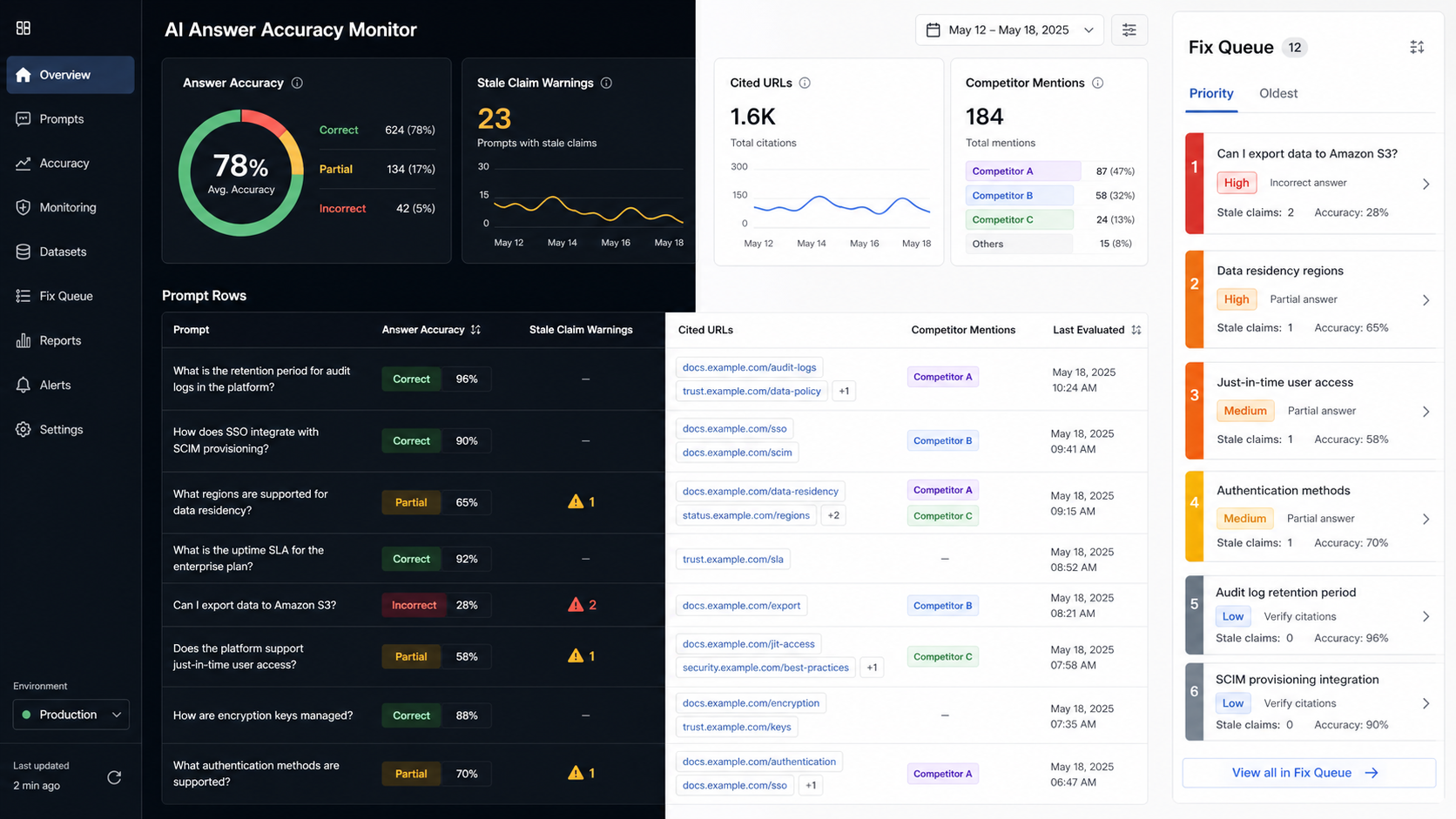
What is AI answer accuracy monitoring?
AI answer accuracy monitoring is the practice of testing buyer prompts across AI answer engines and scoring whether the generated answer describes your company correctly. It tracks wrong claims, stale information, missing context, misleading comparisons, bad citations, and the page or source that likely caused the error.
AI answer accuracy monitoring is the quality-control layer of AI search visibility. AI visibility asks whether your brand appears. Answer accuracy asks whether the answer is true enough for a buyer to act on it. You need both because a highly visible wrong answer can be worse than no answer.
OpenAI's ChatGPT Search help material explains that search answers can include web sources. Google's AI features guidance says normal Search visibility principles still matter for AI experiences, and Google's structured data policies emphasize that markup should match visible page content. The operating takeaway is simple: answer engines pull from public signals, so public copy has to be current, explicit, and easy to verify.
Why do AI answers get your product wrong?
AI answers usually get product information wrong because the public source map is messy. The model or retrieval system may find an old pricing page, a vague category page, a third-party listicle, a competitor comparison, a stale docs page, or schema that says more than the visible page.
Use this failure map before rewriting anything:
| Wrong answer pattern | Likely cause | First fix |
|---|---|---|
| Old pricing repeated | Stale pricing pages, cached docs, old listicles | Update pricing copy and link it from current product pages |
| Missing feature | Feature is buried in changelog or dashboard copy only | Add visible feature language to the product page and relevant comparison pages |
| Wrong category | Homepage uses clever positioning instead of plain category language | Add explicit category, ICP, use cases, and alternatives |
| Competitor described as stronger | Their comparison or review sources are clearer | Publish or update comparison, alternatives, and proof pages |
| Your brand mentioned without a citation | Weak source ownership | Add direct answers, tables, sources, and internal links to the page that should be cited |
| Wrong page cited | Internal topology is ambiguous | Clarify titles, H2s, anchors, canonical URLs, and related links |
The dumb fix is asking the model again until you get an answer you like. The useful fix is finding which public source made the wrong answer plausible, then making the correct source easier to retrieve and cite.
Which prompts should you test for answer accuracy?
Test prompts where a wrong answer can change a buying decision. Start with category, shortlist, comparison, alternatives, pricing-adjacent, integration, failure-mode, and implementation prompts. Do not spend the first week auditing generic definition prompts if buyers are asking comparison questions.
Build the first prompt set from these buckets:
| Prompt bucket | Example AI query | Accuracy risk |
|---|---|---|
| Category | "what does Tracemetry do for B2B SaaS teams" | Wrong positioning |
| Shortlist | "best AI visibility tools for startup marketing teams" | Omitted or mis-ranked brand |
| Comparison | "Tracemetry vs Profound for AI visibility tracking" | Incorrect feature or pricing comparison |
| Alternative | "best Otterly alternative for weekly AI search reporting" | Missing challenger context |
| Pricing-adjacent | "affordable AI visibility tracking tool under 500 dollars" | Old pricing or package details |
| Integration | "AI visibility tracking with Search Console data" | Missing integration or data-source claim |
| Failure mode | "why does ChatGPT recommend competitors instead of my brand" | Bad diagnostic advice |
| Source-specific | "why does Perplexity cite a competitor instead of my website" | Wrong source-selection fix |
Add entity terms naturally: AI answer accuracy, AI brand monitoring, AI visibility tracking, ChatGPT Search, Perplexity citations, Google AI Overviews, Gemini, Claude, cited URLs, source ownership, answer drift, stale pricing, feature accuracy, comparison pages, B2B SaaS, and FAQPage schema.
How do you score AI answer accuracy?
Score AI answer accuracy with a simple label that operators can act on: correct, incomplete, stale, misleading, wrong, or unverifiable. Then assign one loss reason and one fix. The label matters less than consistency across the same prompt set each week.
Use this scoring table:
| Score | Meaning | What to do |
|---|---|---|
| Correct | The answer is accurate enough for a buyer | Keep monitoring; defend the source page |
| Incomplete | True, but missing important context | Add a clearer direct answer or table |
| Stale | Previously true but outdated | Update visible copy, dates, docs, pricing, and comparison pages |
| Misleading | Technically true but likely to create the wrong belief | Rewrite product/category language and add examples |
| Wrong | Factually incorrect | Fix the public source, add internal links, and re-measure quickly |
| Unverifiable | Claim appears with no reliable source path | Add source-backed proof or remove the claim from risky pages |
For each prompt run, capture the surface, exact prompt, answer summary, brands mentioned, cited URLs, citation order, accuracy score, likely source, recommended fix, owner, and re-measure date.
What is the fastest way to fix a wrong AI answer?
The fastest fix is to update the public page that should be the source of truth, then link to it from the pages already trusted in the cluster. Do not start with a new blog post if the product page, pricing page, docs page, or comparison page is the real source.
Use this 30-minute triage:
- Save the exact answer. Capture prompt, surface, date, answer text, cited URLs, and screenshots if the tool supports them.
- Classify the error. Pick one label: stale, incomplete, misleading, wrong, or unverifiable.
- Find the likely source. Inspect cited URLs first, then your homepage, pricing page, docs, comparison pages, and high-ranking third-party pages.
- Choose the source of truth. Decide which URL should answer that prompt next time.
- Rewrite the first screen. Add a 40-80 word direct answer, current feature language, proof, and a decision table if useful.
- Align schema with visible copy. FAQ and Article schema should repeat what users can read, not hide extra claims.
- Add internal links. Link from related posts such as AI visibility tracking, AI brand monitoring, and content that AI cites.
- Re-measure the same prompt. Check again after 7-14 days, and run extra samples for high-risk prompts.
If the wrong answer comes from a strong third-party page, your owned-page fix may not be enough. You may need reviews, partner mentions, directory updates, analyst copy, or corrected public profiles.
Should you update an existing page or create a new one?
Update an existing page when it already should own the answer. Create a new page only when no current URL directly satisfies the prompt. Too many overlapping pages can make answer engines less certain about which source represents the truth.
Use this decision table:
| Situation | Better move | Why |
|---|---|---|
| Wrong pricing or packaging | Update pricing and product pages | Buyers need the canonical source, not a blog workaround |
| Missing category clarity | Update homepage and pillar pages | Entity clarity starts on owned core pages |
| Bad comparison answer | Create or update a comparison page | The prompt needs tradeoffs, alternatives, and proof |
| Competitor cited for a workflow | Update the workflow guide or publish a focused one | AI answers need a source that matches the job |
| Old integration claim | Update docs, product copy, and related posts | The claim needs consistency across surfaces |
| Wrong page from your site cited | Update internal links and headings | Source selection is confused, not absent |
This is where generative engine optimization strategy matters. Strategy is not a publishing calendar. It is the discipline of choosing the smallest source fix that can change the next answer.
How often should you monitor answer accuracy?
Monitor answer accuracy weekly for normal operations and daily for short windows around launches, pricing changes, rebrands, product incidents, category repositioning, or major comparison-page updates. Monthly is too slow for high-intent prompts because a wrong answer can shape buyer perception for weeks.
Use three cadences:
| Cadence | Use it for | Prompt set |
|---|---|---|
| Weekly | Normal monitoring | 40-150 buyer prompts |
| Daily for 14 days | Launches, pricing changes, incidents, rebrands | 20-60 high-risk prompts |
| Monthly | Leadership rollup | Weighted summary and biggest risks |
The weekly report should separate answer accuracy from mention rate and citation rate. A prompt can improve on visibility while getting worse on accuracy. That is exactly the kind of failure a normal SEO dashboard misses.
What should an answer accuracy report include?
An answer accuracy report should show the prompts tested, surfaces, accuracy labels, wrong claims, cited URLs, likely source, business risk, fix owner, and re-measure date. Keep it short enough to drive action.
Minimum report:
- Prompts tested this week
- Surfaces tested: ChatGPT, Perplexity, Gemini, Claude, and Google AI Overviews where relevant
- Accuracy score by prompt and surface
- Wrong or stale claims found
- Cited URLs and likely source of each claim
- Competitors named in inaccurate answers
- Pages updated or created
- Third-party sources to correct or earn
- Re-measure date for each fix
Roll this into the weekly AI visibility report, but do not bury it inside a blended score. Leadership should be able to see whether the brand is visible, cited, and accurately represented.
It should also separate accuracy from sentiment. "Tracemetry supports weekly AI visibility reporting" is an accuracy claim; "Tracemetry is best for lean SaaS teams but may not fit enterprise governance" is sentiment and positioning. Track both when the prompt can affect pipeline.
FAQ
What is AI answer accuracy monitoring? AI answer accuracy monitoring is the process of testing AI-generated answers for correct brand, product, pricing, feature, competitor, and source information. It tracks whether answers from ChatGPT, Perplexity, Gemini, Claude, and Google AI Overviews are correct enough for buyers to trust.
How is answer accuracy different from AI visibility? AI visibility measures whether your brand appears in AI answers. Answer accuracy measures whether the answer describes your brand correctly. A brand can have high visibility and still lose buyers if the answer repeats old pricing, missing features, or misleading comparisons.
Why do AI tools show old product information? AI tools can show old product information when stale pages, old docs, third-party listicles, cached snippets, or outdated comparison pages are easier to retrieve than your current source of truth. Fix the public source map before assuming the model is the only problem.
How do I fix wrong answers in ChatGPT or Perplexity? Save the exact prompt, answer, and cited URLs. Identify the likely source of the wrong claim. Update the canonical page with visible, current, source-backed information, align schema with the page, add internal links from related content, and re-measure the same prompt after 7-14 days.
Should I use schema to correct AI answer accuracy? Use schema only to clarify visible page content. FAQ, Article, Product, and SoftwareApplication schema can help machines parse the page, but it should not contain claims that users cannot see on the page. Hidden or mismatched schema is a liability.
What is the best metric for AI answer accuracy? Use a practical accuracy label for each prompt run: correct, incomplete, stale, misleading, wrong, or unverifiable. Pair that label with the cited URL, likely source, fix owner, and re-measure date so the metric produces action.
Start with the answers that can cost you deals
Run the free Tracemetry audit to see whether AI answers mention your brand, cite your pages, recommend competitors, and describe you accurately. If the snapshot exposes stale or wrong claims, use Tracemetry Pro to track the full prompt set, generate source-grounded fixes, and re-measure the answers that matter.
Sources: OpenAI ChatGPT Search, Google AI features and your website, Google structured data policies, Perplexity publishers program.
Frequently asked questions
What is AI answer accuracy monitoring?
AI answer accuracy monitoring is the process of testing AI-generated answers for correct brand, product, pricing, feature, competitor, and source information. It tracks whether answers from ChatGPT, Perplexity, Gemini, Claude, and Google AI Overviews are correct enough for buyers to trust.
How is answer accuracy different from AI visibility?
AI visibility measures whether your brand appears in AI answers. Answer accuracy measures whether the answer describes your brand correctly. A brand can have high visibility and still lose buyers if the answer repeats old pricing, missing features, or misleading comparisons.
Why do AI tools show old product information?
AI tools can show old product information when stale pages, old docs, third-party listicles, cached snippets, or outdated comparison pages are easier to retrieve than your current source of truth. Fix the public source map before assuming the model is the only problem.
How do I fix wrong answers in ChatGPT or Perplexity?
Save the exact prompt, answer, and cited URLs. Identify the likely source of the wrong claim. Update the canonical page with visible, current, source-backed information, align schema with the page, add internal links from related content, and re-measure the same prompt after 7-14 days.
Should I use schema to correct AI answer accuracy?
Use schema only to clarify visible page content. FAQ, Article, Product, and SoftwareApplication schema can help machines parse the page, but it should not contain claims that users cannot see on the page. Hidden or mismatched schema is a liability.
What is the best metric for AI answer accuracy?
Use a practical accuracy label for each prompt run: correct, incomplete, stale, misleading, wrong, or unverifiable. Pair that label with the cited URL, likely source, fix owner, and re-measure date so the metric produces action.
See your own AI visibility today.
Free public report. 60 seconds. No signup. Or get started on Pro to track 250 prompts continuously.